Mới đây, Google AI đã công bố rằng KELM là một phương thức giảm thiểu mức độ sai lệch, nội dung độc hại trong kết quả tìm kiếm. Đồng thời đây là cách cải thiện độ chính xác thực tế phương pháp gọi là TEKGEN để chuyển đổi các dữ kiện Sơ đồ tri thức thành văn bản ngôn ngữ tự nhiên, sau đó có thể được sử dụng để cải thiện các mô hình xử lý ngôn ngữ tự nhiên
KELM là gì?
KELM là cụm từ viết tắt của Knowledge-Enhanced Language Model Pre-training, tạm dịch là đào tạo trước mô hình ngôn ngữ nâng cao kiến thức.
Trên thực tế có rất nhiều mô hình xử lý ngôn ngữ tự nhiên (natural language processing – NLP) là một nhánh của trí tuệ nhân tạo AI. Trong AI việc xử lý ngôn ngữ tự nhiên là việc cực kỳ khó, vì nó liên quan đến việc tiếp thu và xác định chính xác ý nghĩa của ngôn ngữ. Từ đó giúp máy tính hiểu và giao tiếp với con người thông qua ngôn ngữ của chính chúng ta.
BERT là một ví dụ mô hình xử lý ngôn ngữ tự nhiên dựa trên kho dữ liệu trên web và những tài liệu văn bản. Còn KELM có thể đề xuất thêm những nội dung thực tế đáng tin cậy (nâng cao kiến thức) vào đào tạo trước mô hình ngôn ngữ để cải thiện độ chính xác thực tế và giảm sự sai lệch.

ALT: TEKGEN chuyển đổi dữ liệu có cấu trúc biểu đồ tri thức thành văn bản ngôn ngữ tự nhiên được gọi là KELM Corpus
KELM sử dụng dữ liệu có độ tin cậy cao
Những nhà nghiên cứu của Google đã đề xuất sử dụng
Các nhà nghiên cứu của Google đã đề xuất sử dụng Google Knowledge Graph (Sơ đồ Tri thức Google) để cải thiện độ chính xác thực tế vì chúng là một nguồn dữ kiện đáng tin cậy.
“Các nguồn thông tin thay thế là biểu đồ tri thức (KG – viết tắt của knowledge graph), bao gồm dữ liệu có cấu trúc. Bản chất của các KG là thực tế vì thông tin thường được trích xuất từ các nguồn đáng tin cậy hơn và các bộ lọc sau xử lý và người chỉnh sửa đảm bảo nội dung không phù hợp và không chính xác sẽ bị loại bỏ. “
Liệu Google có đang ứng dụng KELM?
Theo những nguồn thông tin hiện tại chưa thể chắc chắn rằng Google đã và đang sử dụng KELM. Tuy nhiên đây là một phương pháp tiếp cận đào tạo trước mô hình ngôn ngữ đầy hứa hẹn và được sự quan tâm của Google gần đây.
Độ chệch, độ chính xác thực tế và kết quả tìm kiếm
Theo bài báo cáo nghiên cứu đã đề cập đến sự quan trọng của cải thiện độ chính xác thực tế như sau:
“Điều này mang lại những lợi thế sâu xa hơn nữa trong cải thiện độ chính xác thực tế và giảm độc hại trong mô hình ngôn ngữ kết quả.”
Có thể nói nghiên cứu này rất quan trọng bởi vì việc giảm độ lệch và tăng độ chính xác thực tế có thể ảnh hưởng đến cách xếp hạng các trang web. Nhưng KELM vẫn chưa được sử dụng vẫn chưa thể kết luận được những tác động của nó lên kết quả tìm kiếm Google.
Và tất nhiên hiện nay Google không xác nhận hay kiểm tra tính chính xác của kết quả tìm kiếm.
KELM, nếu nó được đưa vào, có thể hình dung được có tác động đến các trang web quảng bá các tuyên bố và ý tưởng không chính xác với thực tế.
KELM có thể ảnh hưởng nhiều hơn kết quả tìm kiếm
KELM Corpus đã được phát hành theo giấy phép Creative Commons ( CC BY-SA 2.0 ).
Điều đó có nghĩa là, về lý thuyết , bất kỳ công ty nào khác (như Bing, Facebook hoặc Twitter) cũng có thể sử dụng nó để cải thiện quá trình đào tạo trước xử lý ngôn ngữ tự nhiên của họ.
Sau đó, có thể ảnh hưởng của KELM có thể mở rộng trên nhiều nền tảng mạng xã hội và tìm kiếm.
KELM cũng có mối quan hệ gián tiếp với MUM
Google cũng quyết định rằng cho đến khi họ đảm bảo được rằng độ sai lệch không ảnh hưởng tiêu cực đến các kết quả mà nó đưa ra. Thì Google sẽ không phát hành thế hệ tiếp theo của thuật toán MUM.
Theo thông báo từ Google MUM:
“Chúng tôi đã thật sự thử nghiệm rất cẩn thận nhiều ứng dụng của BERT được phát hành kể từ năm 2019, MUM sẽ trải qua quá trình giống như chúng tôi áp dụng các mô hình này trong Tìm kiếm.
Cụ thể, chúng tôi sẽ tìm kiếm các mẫu có thể chỉ ra độ sai lệch trong học máy (Machine learning) để tránh đưa sự sai lệch vào hệ thống của chúng tôi ”.
Phương pháp KELM nhắm mục tiêu cụ thể đến việc giảm độ lệch, điều này có thể rất hữu ích để phát triển thuật toán MUM.
Học máy có thể tạo ra kết quả sai lệch
Theo như bài nghiên cứu nói rằng dữ liệu mà các mô hình ngôn ngữ tự nhiên như BERT và GPT-3 sử dụng để đào tạo có thể tạo ra những “nội dung độc hại” có độ sai lệch nhất định.
Trong tin học có một từ GIGO là viết tắt của cụm từ Garbage In – Garbage Out. Có nghĩa là chất lượng đầu vào quyết định một lần rất lớn cho chất lượng đầu ta. Vì vậy nếu bạn huấn luyện thuật toán bằng những quy chuẩn chất lượng nhất thì kết quả sẽ có chất lượng cao tương ứng.
Những gì các nhà nghiên cứu đang đề xuất là cải thiện chất lượng dữ liệu mà các công nghệ như BERT và MUM được đào tạo để loại bỏ các sai lệch.
Knowledge Graph – Sơ đồ trí thức
Biểu đồ tri thức là một tập hợp các dữ kiện ở định dạng dữ liệu có cấu trúc. Dữ liệu có cấu trúc là một ngôn ngữ đánh dấu để truyền đạt thông tin cụ thể theo cách mà máy móc dễ dàng sử dụng.
Trong trường hợp này, thông tin là sự thật về con người, địa điểm và sự vật.
Sơ đồ tri thức của Google được giới thiệu như một cách để giúp Google hiểu mối quan hệ giữa mọi thứ. Vì vậy, khi ai đó hỏi về Washington, Google có thể phân biệt được liệu người đặt câu hỏi đang hỏi về Washington về con người, tiểu bang hay Đặc khu Columbia.
Thông báo năm 2012 của Google đã mô tả biểu đồ tri thức là bước đầu tiên để xây dựng thế hệ tìm kiếm tiếp theo mà chúng tôi hiện đang tận hưởng.
Sơ đồ trí thức và độ chính xác thực tế
Dữ liệu sơ đồ trí thức được sử dụng trong bài nghiên cứu này để cải thiện các thuật toán của Google vì thông tin đáng tin cậy và đáng tin cậy.
Bài báo nghiên cứu của Google đề xuất tích hợp thông tin biểu đồ tri thức vào quá trình đào tạo để loại bỏ các sai lệch và tăng độ chính xác thực tế.
Những gì nghiên cứu của Google đề xuất là gấp đôi.
- Đầu tiên, họ cần chuyển các cơ sở kiến thức thành văn bản ngôn ngữ tự nhiên.
- Thứ hai, kho dữ liệu kết quả, được đặt tên làKnowledge-Enhanced Language Model Pre-training (KELM), sau đó có thể được tích hợp vào đào tạo trước thuật toán để giảm các sai lệch.
Các nhà nghiên cứu giải thích vấn đề như thế này:
“Các mô hình xử lý ngôn ngữ tự nhiên (NLP) lớn được đào tạo trước, chẳng hạn như BERT, RoBERTa, GPT-3, T5 và REALM, tận dụng kho ngữ liệu ngôn ngữ tự nhiên có nguồn gốc từ Web và được tinh chỉnh trên dữ liệu tác vụ cụ thể…
Tuy nhiên, chỉ riêng văn bản bằng ngôn ngữ tự nhiên đã đại diện cho một phạm vi kiến thức hạn chế… Hơn nữa, sự tồn tại của thông tin phi thực tế và nội dung độc hại trong văn bản cuối cùng có thể gây ra sai lệch trong các mô hình kết quả. ”
Từ dữ liệu có cấu trúc trong sơ đồ tri thức đến văn bản ngôn ngữ tự nhiên
Các nhà nghiên cứu chỉ ra rằng một vấn đề khi tích hợp thông tin cơ sở kiến thức vào quy trình đào tạo là dữ liệu cơ sở kiến thức ở dạng dữ liệu có cấu trúc.
Giải pháp là chuyển đổi dữ liệu có cấu trúc biểu đồ tri thức sang văn bản ngôn ngữ tự nhiên bằng cách sử dụng một tác vụ ngôn ngữ tự nhiên được gọi là tạo dữ liệu thành văn bản.
Họ giải thích rằng vì việc tạo dữ liệu thành văn bản đang thách thức họ tạo ra thứ mà họ gọi là “pipeline” gọi là “Text from KG Generator(TEKGEN)” Để giải quyết vấn đề.
TEKGEN Văn bản ngôn ngữ tự nhiên được cải thiện độ chính xác thực tế
TEKGEN là công nghệ mà các nhà nghiên cứu đã tạo ra để chuyển đổi dữ liệu có cấu trúc sang văn bản ngôn ngữ tự nhiên. Đây là kết quả cuối cùng, văn bản thực tế, có thể được sử dụng để tạo kho ngữ liệu KELM, sau đó có thể được sử dụng như một phần của quá trình đào tạo trước học máy để giúp ngăn chặn sự sai lệch xâm nhập vào các thuật toán.
Các nhà nghiên cứu lưu ý rằng việc thêm thông tin biểu đồ kiến thức (kho tài liệu) bổ sung này vào dữ liệu đào tạo dẫn đến cải thiện độ chính xác thực tế.
Bài báo KELM đã xuất bản một minh họa cho thấy cách một nút dữ liệu có cấu trúc được nối và chuyển đổi từ đó thành văn bản tự nhiên (bằng lời nói).
Tôi chia hình minh họa thành hai phần.
Dưới đây là hình ảnh đại diện cho dữ liệu có cấu trúc biểu đồ tri thức. Dữ liệu được nối với văn bản.
Ảnh chụp màn hình Phần đầu tiên của Quy trình Chuyển đổi TEKGEN
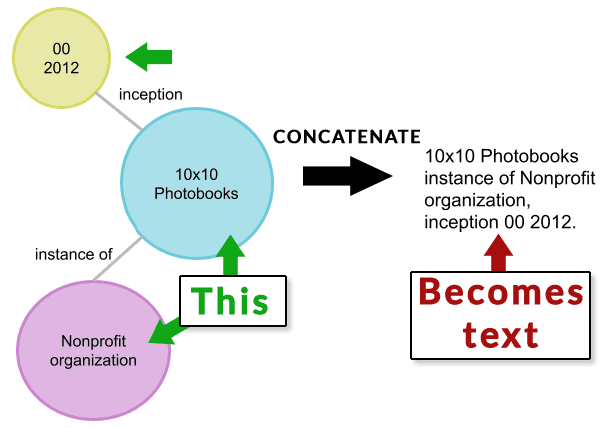
Hình ảnh dưới đây đại diện cho bước tiếp theo của quy trình TEKGEN lấy văn bản được nối và chuyển nó thành văn bản ngôn ngữ tự nhiên.
Ảnh chụp màn hình của Văn bản được chuyển sang Văn bản ngôn ngữ tự nhiên

Tạo KELM Corpus
Có một minh họa khác cho thấy cách tạo ra văn bản ngôn ngữ tự nhiên KELM có thể được sử dụng để đào tạo trước.
Bài báo TEKGEN cho thấy hình ảnh minh họa này cùng với mô tả:
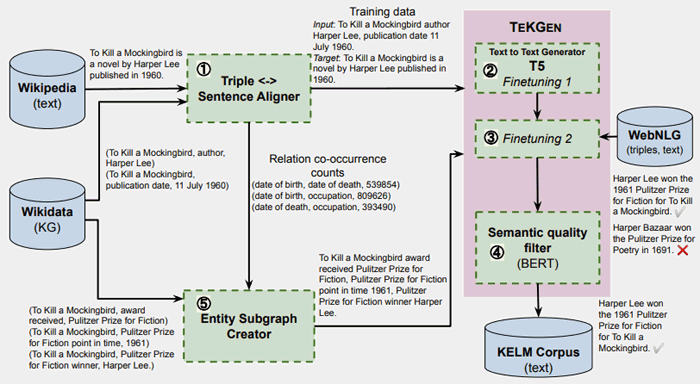
“Ở Bước 1, bộ ba KG được căn chỉnh với văn bản Wikipedia bằng cách sử dụng tính năng giám sát từ xa.
Trong Bước 2 & 3, T5 được tinh chỉnh tuần tự trước tiên trên kho tài liệu này, sau đó là một số bước nhỏ trên kho ngữ liệu WebNLG,
Trong Bước 4, BERT được tinh chỉnh để tạo ra điểm chất lượng ngữ nghĩa cho các câu được tạo gấp ba lần.
`Bước 2, 3 và 4 cùng nhau tạo thành TEKGEN.
Để tạo kho ngữ liệu KELM, trong Bước 5, các đồ thị con của thực thể được tạo bằng cách sử dụng số lượng căn chỉnh của cặp quan hệ từ kho ngữ liệu đào tạo được tạo ở bước 1.
Sau đó, bộ ba trang con được chuyển đổi thành văn bản tự nhiên bằng TEKGEN. ”
KELM làm việc để giảm sai lệch và thúc đẩy độ chính xác
Bài báo KELM được xuất bản trên blog AI của Google nói rằng KELM có các ứng dụng trong thế giới thực. Đặc biệt cho các tác vụ trả lời câu hỏi liên quan rõ ràng đến truy xuất thông tin (tìm kiếm) và xử lý ngôn ngữ tự nhiên (các công nghệ như BERT và MUM).
Google nghiên cứu nhiều thứ, một số trong số đó dường như là khám phá những gì có thể nhưng ngược lại thì có vẻ như là ngõ cụt. Nghiên cứu có thể sẽ không được đưa vào thuật toán của Google thường kết thúc với một tuyên bố rằng cần phải nghiên cứu thêm vì công nghệ này không đáp ứng được kỳ vọng theo cách này hay cách khác.
Nhưng đó không phải là trường hợp của nghiên cứu KELM và TEKGEN. Trên thực tế, bài báo lạc quan về ứng dụng trong thế giới thực của những khám phá. Điều đó có xu hướng mang lại xác suất cao hơn rằng KELM cuối cùng có thể đưa nó vào tìm kiếm ở dạng này hay dạng khác.
Đây là cách các nhà nghiên cứu kết luận bài báo trên KELM để giảm sự thiên vị:
“Điều này có các ứng dụng trong thế giới thực cho các nhiệm vụ đòi hỏi nhiều kiến thức, chẳng hạn như trả lời câu hỏi, nơi cung cấp kiến thức thực tế là điều cần thiết. Hơn nữa, kho ngữ liệu như vậy có thể được áp dụng trong việc đào tạo trước các mô hình ngôn ngữ lớn, và có thể có khả năng giảm độc tính và cải thiện tính thực tế. ”
KELM sẽ sớm được sử dụng chứ?
Thông báo gần đây của Google về thuật toán MUM yêu cầu độ chính xác, điều mà kho dữ liệu KELM được tạo ra. Nhưng ứng dụng của KELM không giới hạn ở MUM.
Thực tế là giảm độ lệch và độ chính xác thực tế là một mối quan tâm quan trọng trong xã hội ngày nay và các nhà nghiên cứu lạc quan về kết quả có xu hướng mang lại cho nó khả năng cao hơn được sử dụng ở một số hình thức trong tương lai để tìm kiếm.
Nhận xét
Đăng nhận xét