Page load time (thời gian tải trang) là một trong những yếu tố quan trọng quyết định trải nghiệm người dùng trên website. Có nhiều nghiên cứu chứng minh rằng, khi tối ưu tốc độ website sẽ cải thiện tỷ lệ chuyển đổi, tăng lượt tải trang và sự hài lòng của khách hàng. Có một minh chứng rõ ràng nhất đến từ đại siêu thị Newegg. Tại đây đã có tổng lượt chuyển đổi tăng một nửa so với trước bằng việc triển khai prefetch để tối ưu hóa tốc độ tải trang.
Trong bài đăng trên blog này, chúng tôi sẽ trình bày quy trình làm việc từ đầu đến cuối để sử dụng dữ liệu navigation của website từ Google Analytics và đào tạo mô hình Machine Learning tùy chỉnh có thể dự đoán các hành động tiếp theo của người dùng. Bạn có thể sử dụng các dự đoán này trong ứng dụng Angular để prefetch các trang ứng cử viên và cải thiện đáng kể trải nghiệm người dùng trên trang web của bạn.
Sơ đồ cấp cao của giải pháp từ TensorFlow
Sử dụng các dịch vụ Google Cloud (BigQuery và Dataflow) để thu thập và xử lý trước dữ liệu Google Analytics của trang web. Những dữ liệu này được gọi là training data và dùng để huấn luyện cho mô hình của thuật toán Machine Learning. Tiếp đến tùy chỉnh bằng cách sử dụng TensorFlow Extended (TFX) để chạy quy trình huấn luyện mô hình của chúng tôi. Từ đó tạo ra một mô hình dành riêng cho website và chuyển đổi nó thành định dạng TensorFlow.js có thể triển khai trên web. Mô hình phía máy khách này sẽ được tải trong ứng dụng web Angular mẫu cho cửa hàng điện tử để trình bày cách triển khai mô hình trong ứng dụng web. Chúng ta hãy cùng tìm hiểu các thành phần này chi tiết hơn.
Data Preparation & Ingestion – Chuẩn bị và thu thập dữ liệu
Google Analytics ghi nhận mỗi lượt truy cập trang dưới dạng một sự kiện, ngoài ra còn cung cấp các thành phần khác như tên trang, thời gian truy cập và thời gian tải trang. Các dữ liệu ở đây là toàn bộ những thứ chúng ta cần để xây dựng mô hình mẫu của mình như:
1. Chuyển đổi dữ liệu thành các ví dụ huấn luyện có chứa các tính năng và nhãn
2. Cung cấp nó cho TFX để huấn luyện
Để xuất những dữ liệu cần thiết từ Google Analytics để lưu trữ trong kho dữ liệu đám mây quy mô lớn có tên là BigQuery. Bằng việc tạo ra đường dẫn Apache Beam, chúng tôi có thể thực hiện được quy trinh sau:
1. Đọc dữ liệu từ BigQuery
2. Sắp xếp và lọc các sự kiện trong một phiên
3. Đi qua từng phiên, tạo các mẫu lấy thuộc tính của sự kiện hiện tại làm đặc điểm và lượt truy cập trang trong sự kiện tiếp theo làm nhãn
4. Lưu trữ các mẫu đã tạo này trong Google Cloud Storage để TFX có thể sử dụng chúng để huấn luyện.
TFX vận hành Beam pipeline trong Dataflow.
Sau đây là một bảng ví dụ, mỗi cột tương ứng với một mẫu huấn luyện.

Các ví dụ trên chỉ chứa hai tính năng đào tạo (cur_page và session_index). Ngoài ra bạn có thể dễ dàng thêm các tính năng bổ sung từ Google Analytics để tạo tập dữ liệu phong phú hơn. Từ đó ra data để huấn luyện nhằm tạo ra một mô hình mạnh mẽ hơn. Để làm như vậy, hãy mở rộng mã sau:
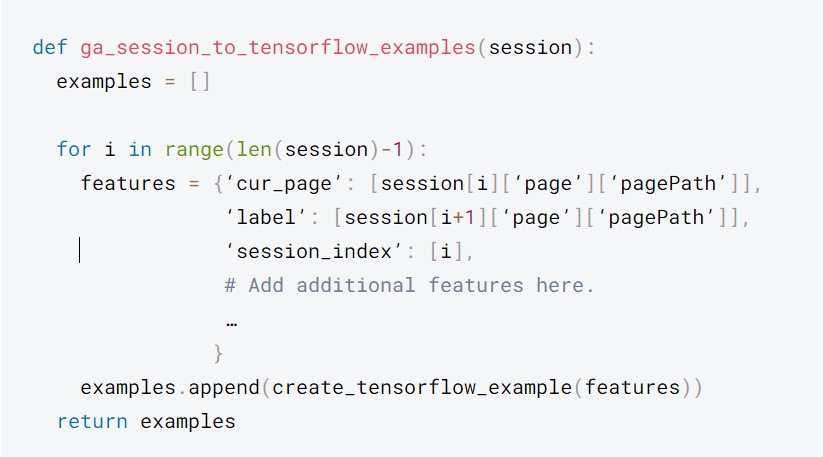
Model Training – bước quan trọng khi tối ưu tốc độ website bằng Tensorflow Extended
Tensorflow Extended (TFX) là một nền tảng ML quy mô t từ đầu đến cuối và được sử dụng để tự động hóa quy trình xác thực dữ liệu, huấn luyện trên quy mô lớn (sử dụng accelerators), đánh giá và xác nhận mô hình đã tạo.
Để tạo một mô hình trong TFX, bạn phải cung cấp chức năng tiền xử lý và chức năng chạy. Hàm tiền xử lý xác định các hoạt động cần được thực hiện trên dữ liệu trước khi nó được chuyển đến mô hình chính. Chúng bao gồm các hoạt động liên quan đến việc chuyển toàn bộ dữ liệu, chẳng hạn như tạo vocab. Hàm run xác định mô hình chính và cách nó được huấn luyện.
Ví dụ của chúng tôi cho thấy cách triển khai preprocessing_fn và run_fn để xác định và huấn luyện mô hình dự đoán trang tiếp theo. Và các pipelines trong ví dụ TFX trình bày cách triển khai các chức năng này cho nhiều trường hợp sử dụng khác.
Tạo ra mô hình có thể triển khai trên web
Để các mô hình được triển khai và ứng dụng lên web nhằm đưa ra những kết quả dự đoán tức thì về người dùng truy cập website. Thì cần phải ứng dụng TensorFlow.js, framework của TensorFlow sử dụng chạy các mô hình machine learning trực tiếp trong browser của client-side.
Bằng cách chạy mã này ở client-side có thể giảm độ trễ liên quan đến lưu lượng truy cập khứ hồi phía server-side, giảm chi phí phía máy chủ và cũng giữ cho dữ liệu của người dùng ở chế độ riêng tư bằng cách không phải gửi bất kỳ dữ liệu phiên nào đến máy chủ.
TFX sử dụng Model Rewriting Library để tự động chuyển đổi giữa các mô hình TensorFlow được đào tạo và định dạng TensorFlow.js. Là một phần của thư viện này, chúng tôi đã thực hiện một TensorFlow.js rewriter. Chúng tôi chỉ cần gọi máy ghi lại này trong run_fn để thực hiện chuyển đổi mong muốn.
Ứng dụng Angular khi tối ưu tốc độ website
Khi chúng ta có mô hình, chúng ta có thể sử dụng nó trong ứng dụng Angular để tối ưu tốc độ website. Trên mỗi điều hướng, chúng tôi sẽ truy vấn mô hình và prefetch những tài nguyên được liên kết với các trang có khả năng được truy cập trong tương lai.
Một giải pháp thay thế sẽ là prefetch các tài nguyên được liên kết với tất cả các đường dẫn điều hướng có thể có trong tương lai, nhưng điều này sẽ có mức tiêu thụ băng thông cao hơn nhiều. Bằng machine learning chúng tôi chỉ có thể dự đoán các trang có khả năng được sử dụng tiếp theo và giảm số lượng xác thực sai.
Tùy thuộc vào các chi tiết cụ thể của ứng dụng, chúng tôi có thể muốn prefetch các loại nội dung khác nhau. Ví dụ: JavaScript, hình ảnh hoặc dữ liệu. Đối với mục đích của cuộc trình diễn này, chúng tôi sẽ prefetch hình ảnh của các sản phẩm.
Làm sao để triển khai một cách hiệu quả?
Một thách thức là làm thế nào để triển khai cơ chế một cách hiệu quả mà không ảnh hưởng đến thời gian tải ứng dụng hoặc hiệu suất thời gian chạy. Các kỹ thuật để giảm thiểu rủi ro của việc hồi quy hiệu suất mà chúng ta có thể sử dụng là:
– Tải mô hình và TensorFlow.js mà không chặn thời gian tải trang ban đầu
– Truy vấn mô hình khỏi chuỗi chính để chúng tôi không làm rơi khung hình trong chuỗi chính và đạt được trải nghiệm hiển thị 60 khung hình / giây
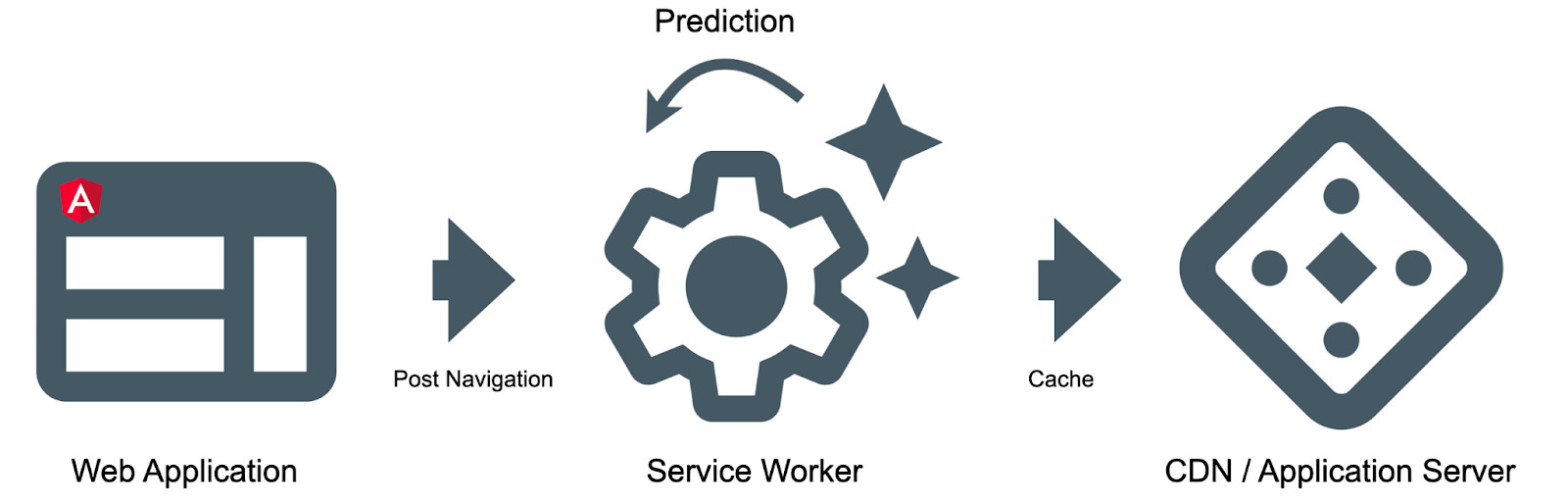
API nền tảng web thỏa mãn cả hai ràng buộc này là service worker . Service worker là một tập lệnh mà trình duyệt của bạn chạy ở chế độ nền trong một chuỗi mới, tách biệt với một trang web. Nó cũng cho phép bạn cắm vào một chu kỳ yêu cầu và cung cấp cho bạn quyền kiểm soát bộ nhớ cache.
Khi người dùng điều hướng trên ứng dụng, chúng tôi sẽ đăng thông báo cho nhân viên dịch vụ với các trang họ đã truy cập. Dựa trên lịch sử điều hướng, nhân viên dịch vụ sẽ đưa ra dự đoán cho việc điều hướng trong tương lai và prefetch các nội dung sản phẩm có liên quan.
Từ trong tệp chính của Angular có thể tải service worker:

Đoạn mã này sẽ tải xuống prefetch.worker.js và chạy trong nền. Bước tiếp theo, chúng tôi muốn chuyển tiếp các sự kiện điều hướng tới nó:

Trong đoạn mã ở trên, có thể theo dõi các thay đổi của các tham số của URL. Khi thay đổi, chúng tôi chuyển tiếp danh mục của trang cho nhân viên dịch vụ.
Trong quá trình triển khai service worker, chúng ta cần xử lý các thông báo từ luồng chính, đưa ra các dự đoán dựa trên chúng và prefetch thông tin có liên quan. Ở cấp độ cao, điều này trông như sau:

Trong service worker cần theo dõi các thông báo từ chuỗi chính. Khi nhận được một thông báo bắt đầu trigger, đưa ra các dự đoán và prefetch dữ liệu.
Trong chức năng prefetch, chúng tôi dự đoán trước, đó là những trang mà người dùng có thể truy cập tiếp theo. Sau đó, chúng tôi lặp lại tất cả các dự đoán và tìm nạp các tài nguyên tương ứng để cải thiện trải nghiệm người dùng trong điều hướng tiếp theo.
Nguồn: Speed-up your sites with web-page prefetching using Machine Learning
Nhận xét
Đăng nhận xét