Crawl và Index là gì? Những lỗi thường gặp trong quá trình Google thu thập dữ liệu và cách khắc phục

Bài viết hôm nay sẽ giải thích Google Crawl và Google Index trong SEO là gì. Tổng hợp những lỗi thường gặp trong quá trình Google thu thập dữ liệu bài viết và lập chỉ mục cùng cách khắc phục.
Sẽ không còn những ngày chờ Google xếp hạng bài viết trong vô vọng nữa mà bằng những cách sau bạn sẽ thoát khỏi thế bị động trong công việc này.
Google Crawl là gì
Google Crawl là thuật ngữ trong SEO ám chỉ việc Google theo dõi các liên kết và thu thập dữ liệu trên website. Bằng cách sử dụng bot chạy khắp các trang web của bạn( hoặc bất kỳ trang nào khác), Google cũng theo dõi các trang khác được liên kết trong website đấy.
Đây là một trong những lý do tại sao phải tạo sơ đồ trang web, vì để các bot Google có thể sử dụng những liên kết có trong các bài viết để nhìn sâu hơn vào một trang web.
Google Index là gì
Google Index hay còn gọi là quá trình thêm các trang web và lập chỉ mục bài viết vào Google search.
Mỗi bài đăng và trang WordPress đều mặc định được Index nhưng có thể sử dụng tag meta (index hoặc no-index) để cho phép hoặc ngăn cản quá trình Google thu thập dữ liệu.
Lưu ý rằng không nên Index những thứ không cần thiết như tag, danh mục và những thứ không cần thiết khác.
>> Cập nhật mới của Google ảnh hưởng gì đến lượt truy cập website?
Những lỗi thường gặp và cách khắc phục
1. Google Crawl và Google Index gặp vấn đề với thẻ Meta Tags hoặc robots.txt
Đây là vấn đề khá dễ phát hiện và giải quyết bằng việc kiểm tra thẻ meta và tệp robots.txt. Vì nó dễ nên có thể ưu tiên xem xét vấn đề này đầu tiên. Google có thể không nhìn thấy toàn bộ trang web hoặc một số trang nhất định vì một lý do đơn giản là website không cho phép thu thập chúng
Có một số lệnh bot, sẽ ngăn chặn việc thu thập dữ liệu trang. Vậy nên hãy lưu ý rằng việc sử dụng những lệnh này đúng cách sẽ giúp đưa ra hướng chính xác cho bot thu thập thông tin các trang mong muốn.
1.1. Chặn trang index thông qua thẻ meta robots
Nếu làm điều này bot tìm kiếm sẽ không xem nội dung bài viết mà chuyển thẳng sang trang tiếp theo.
Bạn có thể sửa sự cố này bằng cách kiểm tra xem code có chứa lệnh này hay không:
< meta name=”robots” content=”noindex” />/p>
1.2. Cách NoFollow links ảnh hưởng đến Google Crawl và Google Index
Trong trường hợp này, trang vẫn được Google Crawl và Index nhưng các link được gắn thẻ Nofollow sẽ không được bot google truy cập vào. Có hai loại lệnh Nofollow:
- Cho toàn bộ trang:
< meta name=”robots” content=”nofollow”>
Đây là lệnh khiến Google không truy cập vào bất kỳ liên kết nào trong trang
- Cho một liên kết duy nhất:
href= “pagename.html” rel=”nofollow”/>
Đây là lệnh khiến Google chỉ truy cập vào một liên kết được chỉ định cụ thể
1.3. Chặn Google Crawl và Google Index thông qua robots.txt
Robots.txt là tệp đầu tiên trên trang web mà trình thu thập xem xét. Nếu thấy nó như thế này:
User-agent: *
Disallow: /
Có nghĩa là tất cả trang web đều bị chặn lập chỉ mục.
Đôi khi có thể xảy ra trường hợp chỉ một số trang hoặc phần nhất đinh bị chặn, ví dụ:
User-agent: *
Disallow: /products/
Trong trường hợp này bất kỳ trang nào trong thư mục con Products sẽ bị chặn lập chỉ mục do đó không có mô tả sản phẩm nào được hiển thị trên Google.
Lỗi liên kết nội bộ bị hỏng khiến Google không Crawl và Index được
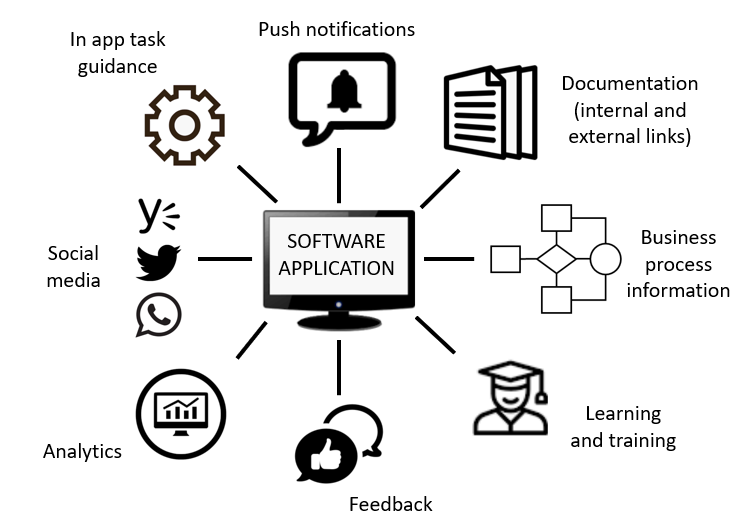
Đây là một lỗi rất tệ không chỉ đối với người dùng mà còn cả quá trình thu thập dữ liệu của Google. Mỗi trang mà bot tìm kiếm lập chỉ mục (hoặc cố gắng lập chỉ mục) mà liên kết bị hỏng, chúng sẽ không đến được trang hoặc bài viết có liên quan hoặc chất lượng.
Dùng Google Search Console hoặc kiểm tra liên kết bị hỏng trong SEMrush sẽ giúp xác định để loại bỏ sự cố này.
2.1. URL error khiến Google không Crawl và Index được
Lỗi URL thường gặp do các liên kết chèn vào trang (liên kết văn bản, liên kết hình ảnh, liên kết biểu mẫu) bị hỏng. Đảm bảo kiểm tra xem liên kết đã được nhập chính xác chưa.
2.2. Quá trình Google Crawl và Google Index không được do URL quá cũ
Nếu gần đây bạn đã di chuyển trang web, xóa hàng loạt hoặc thay đổi cấu trúc URL, bạn cần kiểm tra kỹ vấn đề này. Đảm bảo rằng bài viết không liên kết đến URL cũ hoặc đã xóa.
2.3. Trang bị từ chối truy cập ảnh hưởng xấu đến quá trình Google Crawl và Google Index
Nếu bạn thấy nhiều trang trong website bị lỗi 403 thì rất có thể những trang này chỉ người dùng đã đăng ký mới truy cập được. Đánh dấu các liên kết này là Nofollow để Google không thu thập dữ liệu từ các trang này.
3. Lỗi máy chủ 5xx
3.1. Sự cố Server error khiến Google không thể Crawl và Index trang web
Một số lượng lớn lỗi 5xx ( ví dụ: 502 error) có thể là tín hiệu về sự cố máy chủ. Để giải quyết chúng bạn hãy cung cấp danh sách trang có lỗi cho người chịu trách nhiệm phát triển và bảo trì web. Bộ phận bảo trì sẽ xử lý các lỗi hoặc vấn đề cấu hình trang web gây ra lỗi máy chủ.
3.2. Công suất server bị hạn chế khiến trang web ngừng phản hồi khi Google Crawl và Index
Nếu máy chủ bị quá tải, nó có thể ngừng phản hồi yêu cầu của người dùng và bot Google. Khi điều này xảy ra, khách hàng truy cập nhận được thông báo “Connection timed out”. Vấn đề này chỉ có thể giải quyết cùng với chuyên gia bảo trì trang web, bên bảo trì sẽ ước tính xem có nên tăng dung lượng máy chủ lên để đáp ứng đủ nhu cầu hay không.
3.3. Cấu hình sai máy chủ trang web khiến quá trình Crawl và Index bị chặn
Đây là một vấn đề phức tạp, nó có thể xảy ra do cấu hình máy chủ cụ thể là do ảnh hưởng của tường lửa trong ứng dụng web (ví dụ: Apache mod_security) chặn bot Google và các bot tìm kiếm khác theo mặc định. Với trường hợp này mọi thứ phải được xác định và giải quyết bởi những người có chuyên môn.
4.Sự cố với Sitemap XML
4.1. Lỗi định dạng
Có một số loại lỗi định dạng như: URL không hợp lệ hoặc thẻ tag bị thiếu
Bạn hoàn toàn có thể phát hiện ra rằng tệp sitemap trang web bị robots.txt chặn. Điều này có nghĩa là các bot không thể truy cập vào nội dung sitemap trang web.
4.2. Các trang sai trong sơ đồ trang web
Bạn có thể xem xét được mức độ liên quan của các URL trong sơ đồ trang web đối với nội dung bài viết. Hãy xem kỹ các liên kết có trong sitemap trang web và đảm bảo rằng mỗi URL đều có liên quan, được cập nhật và chính xác (Không có lỗi chính tả hoặc đánh dấu sai). Nếu bị hạn chế và không thể đi khắp trang web thì bot chỉ báo sơ đồ trang web có thể giúp chúng lập chỉ mục những trang có giá trị trước tiên.
Đừng đánh lừa bot bằng các hướng dẫn gây tranh cãi: hãy đảm bảo rằng các URL trong sơ đồ trang web không bị các lệnh meta hoặc robots.txt chặn lập Google Index.
5. Google Crawl và Google Index không được do cấu trúc website bị lỗi
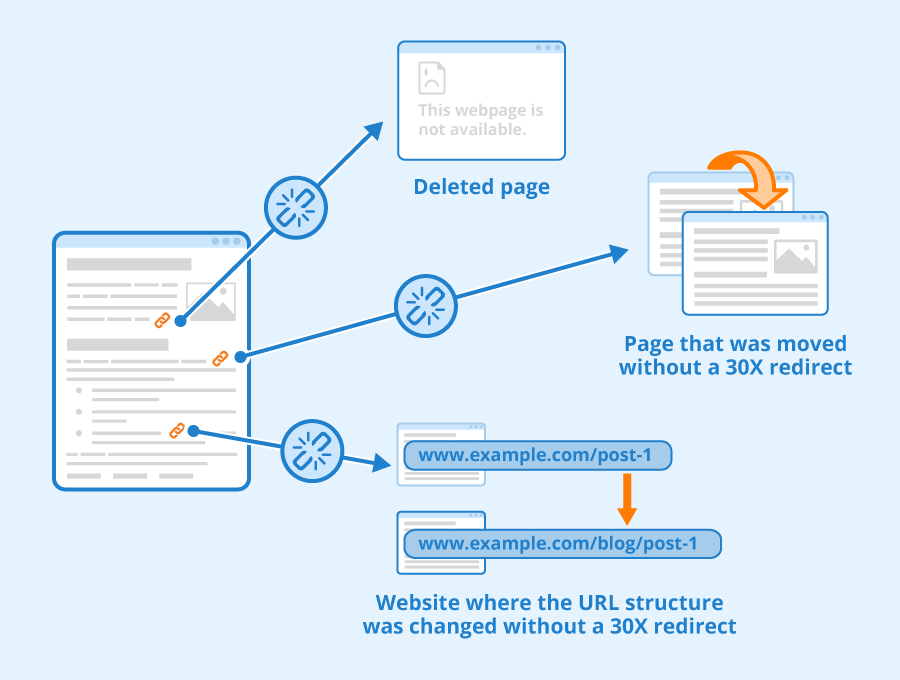
Các vấn đề khi gặp lỗi này là khó giải quyết nhất. Đây là lý do tại sao bạn nên thực hiện những bước trên rồi mới chuyển sang kiểm tra trường hợp này.
Những vấn đề liên quan đến cấu trúc trang web có thể làm mất phương hướng hoặc chặn quá trình bot Google Index hoặc Crawl.
5.1. Google Crawl và Google Index gặp vấn đề với internal link
Trong cấu trúc trang web được tối ưu hóa chính xác, tất cả các trang tạo thành một chuỗi không thể tách rời để bot thu thập dữ liệu và tiếp cận trang web dễ dàng
Một website chưa được tối ưu hóa cấu trúc thì nhất định các trang web nằm ngoài tầm nhìn bot thu thập thông tin. Có nhiều lý do khác nhau cho vấn đề này, chúng ta có thể tham khảo những đề xuất sau:
- Trang muốn được xếp hạng không liên kết với bất kỳ trang nào khác trên trang web, từ đây bot Google không thể Crawl hay Index bài viết trên trang web của bạn được.
- Quá nhiều chuyển đổi giữa trang chính và trang muốn xếp hạng. Hãy chuyển đổi từ 4 liên kết trở xuống nếu không bot sẽ có thể không đến được bài viết.
- Hơn 3000 liên kết đang hoạt động trong trang, quá nhiều đối với trình thu thập dữ liệu
- Các liên kết được ẩn trong các phần tử trang web không thể lập chỉ mục: biểu mẫu, khung, plugin được yêu cầu gửi (trước hết là Java và Flash)
Trong hầu hết các trường hợp, internal links không phải là thứ có thể giải quyết ngay lập tức. Cần đánh giá cấu trúc trang web với sự cộng tác của các nhà phát triển.
5.2. Chuyển hướng sai khiến Google Crawl và Google Index khó khăn hơn
Chuyển hướng là cần thiết để người dùng đến được một trang khác có liên quan đến nội dung bài viết. Dưới đây là những gì có thể bỏ qua khi làm việc với chuyển hướng.
- Chuyển hướng tạm thời thay vì vĩnh viễn: sử dụng chuyển hướng 302 hoặc 307 là một tín hiệu để Google quay lại trang nhiều lần.
- Vòng lặp chuyển hướng: Có thể xảy ra trường hợp hai trang được chuyển hướng đến nhau. Vì vậy bot bị vướng vào một vòng lặp và lãng phí rất nhiều thời gian. Kiểm tra kỹ và xóa các chuyển đổi hướng chung cuối cùng.
5.3. Google Crawl và Google Index bị ảnh hưởng xấu do tốc độ tải chậm
Các trang tải càng nhanh, trình thu thập thông tin lướt qua chúng càng nhanh. Mỗi giây đều quan trọng và vị trí của trang web trong SERP có tương quan với tốc độ tải.
Sử dụng Google PageSpeed Insights để xác minh xem trang web có đủ nhanh hay không. Nếu tốc độ tải có thể ảnh hưởng người dùng thì nhất định có một vài yếu tố ảnh hưởng đến nó.
Yếu tố phía server: Website có thể chậm vì một lý do đơn giản là băng thông kênh hiện tại không còn đủ nữa.
Yếu tố giao diện người dùng: Một trong những vấn đề thường gặp nhất là mã chưa được tối ưu hóa. Nếu nó chứa nhiều tệp lệnh và plug-in, trang web của bạn đang gặp rủi ro. Đừng quên thường xuyên xác minh rằng hình ảnh, video và các nội dung khác của bạn được tối ưu hóa và không làm chậm tốc độ tải trang.
5.4. Trang trùng lặp do cấu trúc trang web ảnh hưởng xấu đến việc Google Crawl và Index
Nội dung trùng lặp là vấn đề thường gặp nhất về SEO, được tìm thấy ở 50% các trang web theo nghiên cứu gần đây của SEMrush. Google dành thời gian giới hạn cho mỗi trang web, vì vậy lập chỉ mục cùng một nội dung là không đúng. Một vấn đề khác là các trình Crawl của Google không biết bản sao nào đáng tin cậy hơn và có thể ưu tiên các trang sai nếu bạn không sử dụng các quy tắc chuẩn để làm rõ mọi thứ.
Để khắc phục sự cố này, bạn cần xác định các trang trùng lặp và ngăn việc thu thập thông tin bằng một trong những cách sau:
- Xóa các trang trùng lặp
- Đặt các thông số cần thiết trong robots.txt
- Đặt các thông số cần thiết trong thẻ meta
- Đặt chuyển hướng 301
- Sử dụng rel = canonical
5.5. Sử dụng sai JavaScript và CSS giúp Google Crawl và Index tốt hơn
Vào năm 2015, Google đã chính thức tuyên bố miễn là bạn không chặn Google Bot thu thập dữ liệu các tệp JavaScript hoặc CSS của mình, Google thường có thể Crawl và Index các trang web của bạn giống như các trình duyệt hiện đại. Tuy nhiên việc này không phù hợp với các công cụ tìm kiếm khác (Yahoo, Bing, v.v.). Hơn nữa trong một số trường hợp, việc Google Index không đảm bảo được độ chính xác.
6. Sử dụng công nghệ cũ và lỗi thời trong việc thiết kế web hạn chế quá trình Google Crawl và Index
6.1. Nội dung Flash ảnh hưởng đến quá trình Crawl và Index như thế nào
Sử dụng Flash là một bước trượt cho cả trải nghiệm người dùng (các tệp Flash không được hỗ trợ trong một số thiết bị di động). Nội dung văn bản hoặc liên kết bên trong phần tử Flash khó có thể được Crawl và Index bởi Google.
Chúng tôi khuyên các bạn không nên dùng chúng cho website của bạn.
6.2. HTML frames ảnh hưởng đến quá trình Crawl và Index như thế nào
Nếu trang web của bạn chứa các HTML frames, thì sẽ có tốt và xấu đi kèm với nó. Thật tốt vì điều này có thể có nghĩa là trang web của bạn đủ lớn. Tin xấu là các HTML frames đã lỗi thời, được lập chỉ mục kém và bạn cần phải thay thế chúng bằng một giải pháp khác tốt hơn để Google có thể Crawl và Index.
Theo dõi website của bạn hằng ngày
Một trang được tối ưu hóa hoàn hảo không đảm bảo rằng bạn sẽ được xếp hạng ở vị trí hàng đầu nếu nội dung không thể được phân phối đến công cụ do các vấn đề về khả năng Crawl và Index của Google.
Để tìm ra điều gì đang chặn hoặc làm mất phương hướng của Google bot trên trang web của bạn cần phải xem xét nhiều điều. Đó là một nỗ lực vất vả khi cố gắn làm theo cách thủ công. Nhưng việc kiểm tra trang web hằng ngày là điều cần thiết để quá trình Crawl và Index của Google được thuận lợi nhất. Các bạn có thể sử dụng các phần mềm hỗ trợ hoặc các tool phục vụ SEO khác nhưng mọi việc vẫn phải được giải quyết bằng chính công sức của bản thân.
Nhận xét
Đăng nhận xét